
瞌睡检测是一种汽车安全技术,有助于防止驾驶员在驾驶时睡着了造成的事故。根据 NHTSA(美国国家公路交通安全管理局)的数据,警方报告的 91,000 起车祸涉及疲劳驾驶。这些车祸导致 2017 年估计有 50,000 人受伤和近 800 人死亡。目前,方法主要集中在使用深度学习或机器学习技术进行眨眼检测,但是,如果司机戴墨镜怎么办?
如果我们同时考虑驾驶员的头部倾斜、打哈欠和其他因素会怎样?是的,这正是本文所做的。
在进入特征提取部分之前,从“ULg 多模态嗜睡数据库”(也称为DROZY )中获取数据,该数据库包含各种类型的嗜睡相关数据(信号、图像等)。
该数据集包含大约 45 个视频剪辑,这些剪辑按照卡罗林斯卡嗜睡量表 (KSS) 进行标记。KSS 量表范围从 1 到 9,其中 1 表示非常警觉,9 表示非常困。
由于该数据集中缺少数据和标签,因此将标签从 1-9 转换为 1-3,分别表示无嗜睡、中度嗜睡和高度嗜睡。本来会使用视频分类过程,但由于数据不够,先提取特征并将它们用作我的模型输入。这样,模型将使用更少的数据达到更准确的效果。
特征提取
对于这个特定任务,我将使用 TensorFlow-GPU 2.6 和 python 3.6 以及使用 pip 预安装的库 open-cv、dlib、scipy。
特征提取所需的所有库:
from scipy.spatial import distance as dist
from imutils.video import FileVideoStream
from imutils.video import VideoStream
from imutils import face_utils
import numpy as np
import argparse
import imutils
import time
import dlib
import cv2
import datetime
import csv
import os
import math
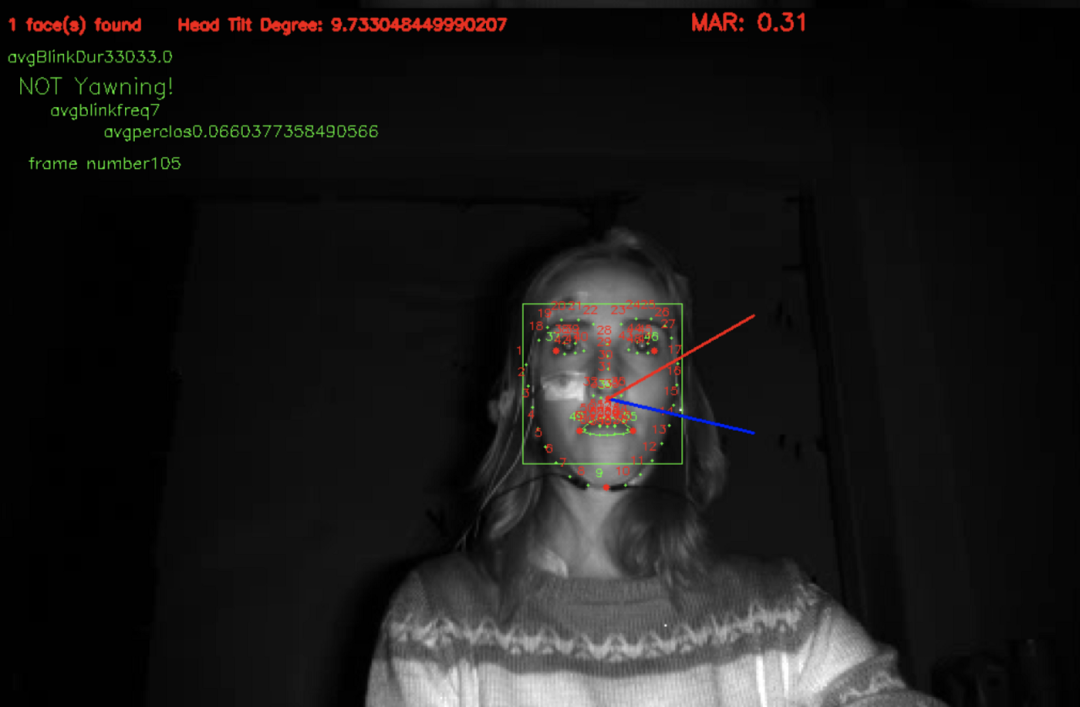
平均眨眼持续时间:眼睛纵横比低于 0.3 然后高于 0.3 的持续时间被检测为眨眼。眨眼发生的时间称为眨眼持续时间。平均每分钟眨眼持续时间以计算平均眨眼持续时间。
# grab the indexes of the facial landmarks for the left and
# right eye, respectively
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
def eye_aspect_ratio(eye):
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
C = dist.euclidean(eye[0], eye[3])
ear = (A + B) / (2.0 * C)
return ear
眨眼频率:每分钟眨眼的次数称为眨眼频率。
def time_difference(start_time, end_time):
start_time = start_time.split()
for i in range(0,8):
hours = int(start_time[3])
mins = int(start_time[4])
secs = int(start_time[5])
milisecs = int(start_time[6])
microsecs = int(start_time[7])
#converting it to microsecs
t1, m1, s1, ms1, mis1 = hours, mins, secs, milisecs, microsecs
start_time_microsecs = mis1 + 1000*(ms1 + 1000*(s1 + 60*(m1 + 60*t1)))
end_time = end_time.split()
for x in range(0,8,1):
hours = int(end_time[3])
mins = int(end_time[4])
secs = int(end_time[5])
milisecs = int(end_time[6])
microsecs = int(end_time[7])
t2, m2, s2, ms2, mis2 = hours, mins, secs, milisecs, microsecs
end_time_microsecs = mis2 + 1000*(ms2 + 1000*(s2 + 60*(m2 + 60*t2)))
#finding the duration of blink
time_differ = end_time_microsecs - start_time_microsecs
#print 'time_difference in microsecs = ', time_differ
return time_differ
嘴部纵横比:计算 MAR 以检测一个人是否在打哈欠。
(omouth, emouth) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]
def mouth_aspect_ratio(mouth):
# compute the euclidean distances between the two sets of
# vertical mouth landmarks (x, y)-coordinates
A = dist.euclidean(mouth[2], mouth[10]) # 51, 59
B = dist.euclidean(mouth[4], mouth[8]) # 53, 57
# compute the euclidean distance between the horizontal
# mouth landmark (x, y)-coordinates
C = dist.euclidean(mouth[0], mouth[6]) # 49, 55
# compute the mouth aspect ratio
mar = (A + B) / (2.0 * C)
# return the mouth aspect ratio
return mar
头部姿态:每帧计算不同的角度,得到头部的姿态。
def getHeadTiltAndCoords(size, image_points, frame_height):
focal_length = size[1]
center = (size[1]/2, size[0]/2)
camera_matrix = np.array([[focal_length, 0, center[0]], [
0, focal_length, center[1]], [0, 0, 1]], dtype="double")
dist_coeffs = np.zeros((4, 1)) # Assuming no lens distortion
(_, rotation_vector, translation_vector) = cv2.solvePnP(model_points, image_points,
camera_matrix, dist_coeffs,
flags = cv2.SOLVEPNP_ITERATIVE) # flags=cv2.CV_ITERATIVE)
(nose_end_point2D, _) = cv2.projectPoints(np.array(
[(0.0, 0.0, 1000.0)]), rotation_vector, translation_vector, camera_matrix, dist_coeffs)
#get rotation matrix from the rotation vector
rotation_matrix, _ = cv2.Rodrigues(rotation_vector)
#calculate head tilt angle in degrees
head_tilt_degree = abs(
[-180] - np.rad2deg([rotationMatrixToEulerAngles(rotation_matrix)[0]]))
#calculate starting and ending points for the two lines for illustration
starting_point = (int(image_points[0][0]), int(image_points[0][1]))
ending_point = (int(nose_end_point2D[0][0][0]), int(nose_end_point2D[0][0][1]))
ending_point_alternate = (ending_point[0], frame_height // 2)
return head_tilt_degree, starting_point, ending_point, ending_point_alternate
这就是我的特征提取过程中的样子。
是时候制作模型了!
由于我们已经完成了特征选择部分,我们不必构建复杂的模型。我将使用人工神经网络
import numpy as np
import sklearn
from sklearn import preprocessing
#from sklearn.datasets.samples_generator import make_blobs
#from sklearn.preprocessing import LabelEncoder, StandardScaler
import csv
import os
from tensorflow import keras
import random
from keras.models import Sequential
from keras.layers import Dense , Dropout, Activation, BatchNormalization
from keras import regularizers
importmatplotlib.pyplot as plt
#from keras.utils import plot_model
import sklearn
from sklearn.metrics import chaos_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
import pickle
from keras.utils import np_utils
from keras import optimizers
from keras.models import load_model
这是深度学习中最简单的模型的设计,但由于特征提取而有效。因为我们计算的是每分钟的瞌睡程度,所以要确保你将你的输入连接起来,然后传递给模型。
#designing the model
model=Sequential()
model.add(Dense(64, input_dim=6, activation='relu'))
model.add(Dropout(0.001))
model.add(Dense(64, input_dim=6, activation='relu'))
model.add(Dropout(0.001))
model.add(Dense(32, input_dim=6, activation='relu'))
model.add(Dense(16, input_dim=6, activation='relu'))
model.add(Dense(4, activation='softmax', use_bias=False))
#compile the model
#adam = keras.optimizers.Adam(lr=0.01)
adam = keras.optimizers.Adam(lr=0.001)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
#fit the model
checkpoint = keras.callbacks.ModelCheckpoint(filepath="trained_models/DrowDet_model(output4).hdf5", period=1)
tbCallBack = keras.callbacks.TensorBoard(log_dir='./scalar',
histogram_freq=0, write_graph=True, write_images=True)
history=model.fit(Xtrain, Ytrain, epochs=50, batch_size=256, callbacks=[checkpoint, tbCallBack], validation_data=(Xval,Yval))
使用准确性与验证准确性和训练损失与验证损失的模型性能。
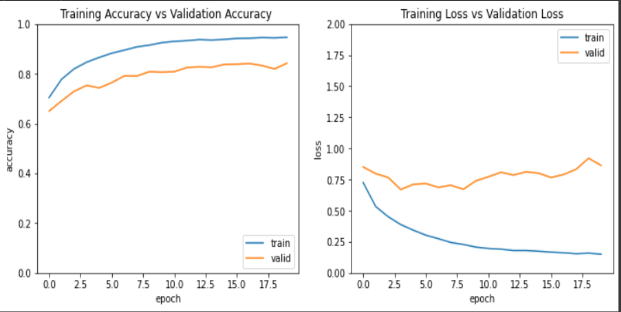
超参数调优模型!我改变了学习率(0.01 -> 0.001),不同的优化器(RMSprop),时期数(20 -> 50)。
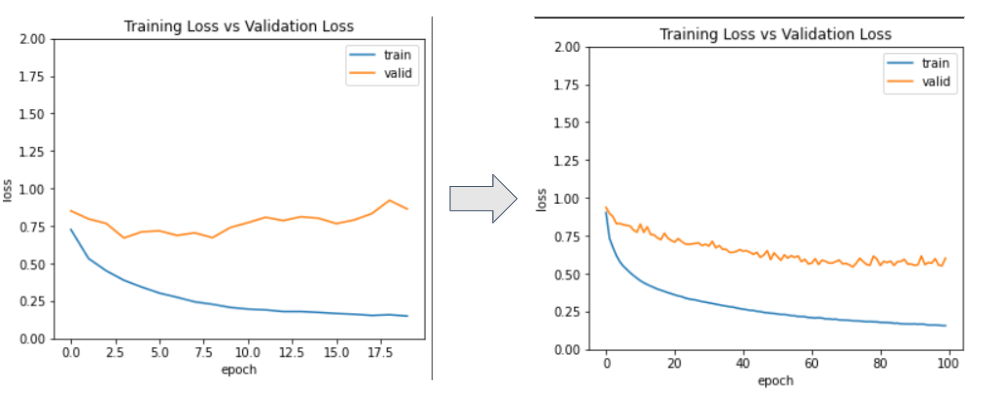
使用 Sklearn 的混淆矩阵,我在测试集上评估了模型,得到了 73% 的准确率和 89% 的训练准确率。再使用大约 4 个隐藏层,我在测试集上得到了大约 74% 的准确率,在训练数据集上得到了 93% 的准确率。
原文标题 : 驾驶员嗜睡分类 - 深度学习








