
介绍
从头开始训练深度学习模型可能是一项乏味的任务。你必须找到正确的训练权重,获得最佳学习率,找到最佳超参数以及最适合你的数据和模型的架构。再加上没有足够的质量数据来训练,以及它需要的计算强度会对我们的资源造成严重损失,这些因素在第一轮就把你击倒。但不要害怕,因为 Fast.ai 等深度学习库会充当我们强有力的助手,让你立即重返赛场。

目录
1. Fast.ai概述
2. 我们为什么要使用 Fast.ai?
· 图像数据包
· LR 查找
· fit_one_cycle
3. 案例研究:紧急与非紧急车辆分类
Fast.ai概述
Fast.ai 是建立在 PyTorch 之上的流行深度学习框架。它旨在通过几行代码快速轻松地构建最先进的模型。它极大地简化了深度学习模型的训练过程,而不会影响训练模型的速度、灵活性和性能。Fast.ai 也支持计算机视觉和 NLP 中最先进的技术和模型。
我们为什么要使用 Fast.ai?
除了 Fast.ai 模型的高生产力和易用性之外,它还确保了我们能够自定义高级 API 而无需干预较低级的 API。Fast.ai 还包含一些非常酷的功能,使其成为初学者最喜欢的深度学习库之一。
图像数据包
图像数据包有助于汇集我们的训练、验证和测试数据,并通过执行所有必需的转换和标准化图像数据来处理数据。
LR 查找
学习率会影响我们的模型学习和适应问题的速度。低学习率会减慢训练过程的收敛速度,而高学习率会导致性能出现令人不快的分歧。
因此,良好的学习率对于模型的令人满意的性能至关重要,而找到最佳学习率就像大海捞针一样。Fast.ai 的“lr_find()”是我们的骑士,它将我们从寻找合适学习率的痛苦中解救出来。
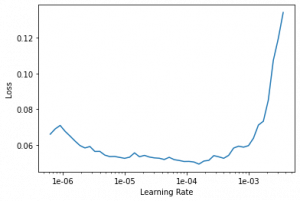
recorder.plot()
lr_find() 的工作原理是最初使用非常低的学习率来训练小批量数据并计算损失。然后它以比前一个稍高的学习率训练下一个小批量。这个过程一直持续到我们到达一个合适的学习率。我们可以使用 recorder.plot() 来获取学习率与 Loss 的图,这简化了选择良好的学习率的任务。选择学习率的依据是哪个学习率为我们的损失提供了最陡的斜率,而不是哪个学习率的损失最低。
fit_one_cycle
fit_one_cycle 方法实现了循环学习率的概念。在这种方法中,我们使用在最小和最大界限值之间波动的学习率,而不是使用固定或指数下降的学习率。
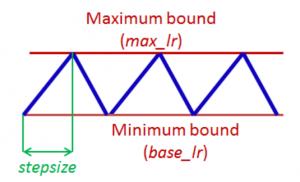
循环学习率。训练神经网络的循环学习率 - https://arxiv.org/pdf/1506.01186.pdf
CLR 中的每个循环由 2 个步骤组成,其中学习率从最小值增加到最大值,下一步反之亦然。假设最佳学习率位于所选的最小值和最大值之间。这里,步长表示用于增加或减少每一步的学习率的迭代次数。
我们使用循环学习率,通过循环数来拟合我们的模型。学习率在训练期间的每个循环中在所选的最小学习率到最大学习率之间振荡。CLR 的使用消除了我们的训练模型陷入鞍点的可能性。
fit_one_cycle 方法还实现了学习率 Annealing 的概念,我们在最后几次迭代中使用减少的 LR。最后一次迭代的学习率通常取为所选最小学习率的百分之一。这可以防止在我们接近它时超出最优值。
案例研究:紧急与非紧急车辆分类
让我们尝试使用 Fast.ai 在 Imagenets 数据集中使用预训练的 Resnet50 模型解决紧急与非紧急车辆分类问题。
导入模块
from fastai.vision import *
from fastai.vision.models import resnet50
使用 ImageDataBunch 进行数据增强
tfms = get_transforms(do_flip=True, flip_vert=True, max_rotate=50, max_lighting=0.1, max_warp=0 )
data = ImageDataBunch.from_df('/content/drive/MyDrive/CV_Vehicle_classification/train_data/images', train, ds_tfms=tfms, label_delim= None, valid_pct=0.2, fn_col=0, label_col=1 , size=299,bs=64).normalize(imagenet_stats)
模型训练
t_cnn1 = cnn_learner(data, resnet50, pretrained=True, metrics=[accuracy])
t_cnn1.fit_one_cycle(5)
最初,让我们使用fit_one_cycle 训练我们的模型 5 个时期。这是为了了解模型的工作原理。
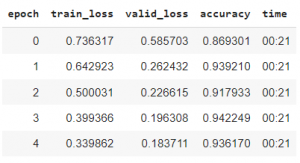
使用 fit_one_cycle() 进行模型训练
在这里,验证损失远小于训练损失。这表明我们的模型拟合不足,与我们需要的模型相去甚远。
解冻图层(unfreeze)
让我们解冻预训练模型的层。这样做是为了让我们的模型学习特定于我们数据集的特征。我们再次拟合我们的模型,看看模型现在是如何工作的。
t_cnn1.unfreeze()
t_cnn1.fit_one_cycle(8)
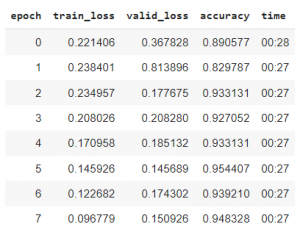
解冻图层并训练模型
学习率查找器
使用 lr_find 和 recorder.plot,我们将能够清楚地了解哪种学习率最适合我们的模型。利用学习率与损失图来选择学习率。
t_cnn1.lr_find()
t_cnn1.recorder.plot()
针对损失图的学习率
可以看到 1e-4 之后的损失逐渐增加。因此,将初始层的学习率选择为 1e-5,将后面的层选择为 1e-4 将是一个明智的想法。
我们再次拟合我们的方法并使用选择的学习率对其进行训练。该模型稍后会被冻结并导出以供以后使用。
t_cnn1.fit_one_cycle(10,max_lr=slice(1e-5, 1e-4))
t_cnn1.freeze()
t_cnn1.export('/content/drive/MyDrive/CV_Vehicle_classification/model/Bmodel_fastai_resnet50.h5')

训练和冻结模型
fit_one_cycle() 中的切片用于实现判别学习。它基本上告诉模型以 1e-5 的学习率训练初始层,以 1e-4 的学习率训练最终层,以及它们之间的层,其值介于这两个学习率之间。
预测
完成所有模型训练后,我们只剩下预测测试数据集的任务了。现在让我们加载我们之前导出的测试数据和 Resnet50 模型,并使用它来预测我们的测试数据。
test_data = ImageList.from_df(test, cols=['image_names'], path='/content/drive/MyDrive/CV_Vehicle_classification/train_data/images')
t_rn50 = load_learner('/content/drive/MyDrive/CV_Vehicle_classification/model/', 'Bmodel_fastai_resnet50.h5', test = test_data)
y_trn50 = t_rn50.TTA(ds_type = DatasetType.Test)
preds = y_trn50[0].argmax(-1)
尾注
瞧!我们现在已经预测了我们的测试数据,而无需花费大量时间来建立一个更大的训练数据集、设计和训练我们的深度学习模型,也不会完全耗尽我们的计算资源。
原文标题 : 使用 Fast ai 进行图像分类








