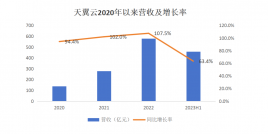
爆炸式增长结束,顶部提升有机会
用于深度学习模型的计算能力的爆炸式增长已经结束了,并为各种任务的计算机性能树立了新的基准。但是这些计算限制的可能影响迫使机器学习转向比深度学习更高效的技术。
过去算力的提升归纳了两个原因:
一个是底部的发展,即计算机部件的小型化,其受摩尔定律制约;
另一个是顶部的发展,是上面提到的软件、算法、硬件架构的统称。
在后摩尔定律时代,提升计算性能的方法,虽然底部已经没有太多提升的空间,但顶部还有机会。
在软件层面,可以通过性能工程(performance engineering)提高软件的效率,改变传统软件的开发策略,尽可能缩短软件运行时间,而不是缩短软件开发时间。另外,性能工程还可以根据硬件的情况进行软件定制,如利用并行处理器和矢量单元。
在算法层面,在已有算法上的改进是不均匀的,而且具有偶然性,大量算法进展可能来源于新的问题领域、可扩展性问题、根据硬件定制算法。
在硬件层面,由于摩尔定律的制约,显然需要改进的是硬件的架构,主要问题就是如何简化处理器和利用应用程序的并行性。
通过简化处理器,可以将复杂的处理核替换为晶体管数量需求更少的简单处理核。由此释放出的晶体管预算可重新分配到其他用途上,比如增加并行运行的处理核的数量,这将大幅提升可利用并行性问题的效率。

深度学习时代AI模型需规模化扩展
现代AI模型需要消耗大量电力,而且对电力的需求正以惊人的速度增长。在深度学习时代,构建一流AI模型所需要的计算资源平均每3.4个月翻一番。
在当今以深度学习为中心的研究范式当中,AI的主要进步主要依赖于模型的规模化扩展:数据集更大、模型更大、计算资源更大。
在训练过程中,神经网络需要为每一条数据执行一整套冗长的数学运算(正向传播与反向传播),并以复杂的方式更新模型参数。
在现实环境中部署并运行AI模型,所带来的能源消耗量甚至高于训练过程。实际上,神经网络全部算力成本中的80%到90%来自推理阶段,而非训练阶段。
因此,数据集规模越大,与之对应的算力与能源需求也在飞速增长。模型中包含的参数量越大,推理阶段所带来的电力需求就越夸张。