前言
大家在读爬虫系列的帖子时常常问我怎样写出不阻塞的爬虫,这很难,但可行。通过实现一些小策略可以让你的网页爬虫活得更久。那么今天我就将和大家讨论这方面的话题。
用户代理
你需要关心的第一件事是设置用户代理。 用户代理是用户访问的工具,并告知服务器用户正在使用哪个网络浏览器访问网站。 如果未设置用户代理,许多网站不会让你查看内容。 如果你正在使用rquests库,可以执行如下操作:

你可以通过在 Google 搜索栏中输入 User-Agent 来获取用户代理的信息,并且它会返回你当前的用户代理信息。
现在,你已经有了一个用户代理,但如何去使用它? 那么,最好的方法是从文本文件、数据库、Python 的列表中选择一个随机的 User-Agent 。 Udger 分享了大量的 UA w.r.t 浏览器。 比如,对于 Chrome 而言,它看起来像这样,对 Firefox 来说,又像这样。 现在让我们来创建一个函数,它将返回一个随机 UA ,你可以在请求中使用:

ua_file.txt 包含一个来自我上面共享的网站的每行 UA 。 函数 get_random_ua 将始终从该文件中返回唯一的 UA 。 你现在可以调用如下函数:

Referrers
接下来你需要设置的是引用。 一般的规则是,如果它是一个列表页面或主页,那么你可以设置该国家的 Google 主页网址。
如果你要抓取各个产品页面,可以在引用中设置相关类别的网址,或者可以找到要抓取的域的反向链接。 我通常使用 SEMRush 来这么做。
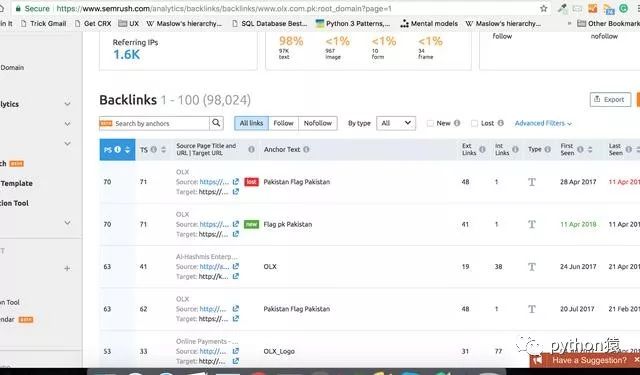
如果你点击查看放大的图像,你可以看到一些链接指向我所需的类别。一旦你收集所有这些真实的反向链接,你可以通过复制逻辑 insideget_random_ua()返回随机引用,并将它们用作引用。 如下所示:

代理IP
我不得不强调这一点。如果认真研究,那么你必须使用多个代理 IP 来避免阻塞。 大多数网站会根据你的服务器或主机提供商的静态 IP 来阻止抓取工具。 这些网站使用智能的工具来确定某个 IP 或 IP 池的方式,并简单地阻止它们。 这也是为什么建议购买几个 IP 地址,50-100个至少要避免阻塞。有许多可用的服务,但我对 Shaders(现在称为 OxyLabs )感到满意。 它们虽然很贵,但服务质量很好。 确保你在订购多个 IP 时,要求提供随机 IP 或至少不遵循 1.2.3.4 到 1.2.3.100 等特定模式。站点管理员将很简单的设置 IP 地址不全部为 1.2.3.* 。 就这么简单。
如果你正在使用请求,你可以像下面这样使用它:

如果你在 Selenium 使用代理 IP ,那么这将有点棘手。
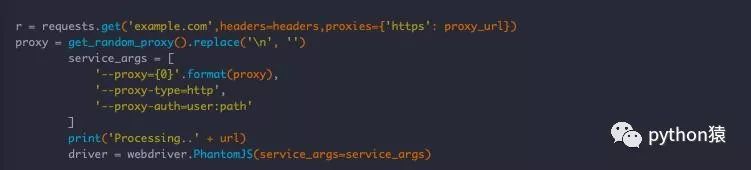
不用说,get_random_proxy() 是返回一个唯一且随机代理的方法,就像上面获得唯一且随机的 UA 和 Referer 一样。
你可以思考一个这样的系统,在系统中你可以设置一个 IP 每天或每小时访问网站频率,如果它超过了,那么它将被放入一个笼子里直到第二天。 我所在的公司设计了一个这样的系统,不仅设置了 IP 访问频率,还记录了哪个 IP 被阻止。 最后,我只是使用代理服务提供者仅替换这些代理。 由于这超出了本文的范围,所以我不会详细介绍它。
Request Heaters
到目前为止,事情你都已经做得很好,但是仍然有些狡猾的网站要求你做更多的事情。当你访问页面的时候他们会查找特定的请求响应头信息,如果特定的头信息没有被发现,他们会阻止内容显示或者展示一个虚假的内容。模拟一个你想访问的网站的请求是非常简单的。例如,比如你正准备访问一个 Craigslist URL ,并且想知道哪个头部信息是需要的。进入 Chrome/Firefox 浏览器,检查正在访问的页面,你应该会看到下面这些内容:
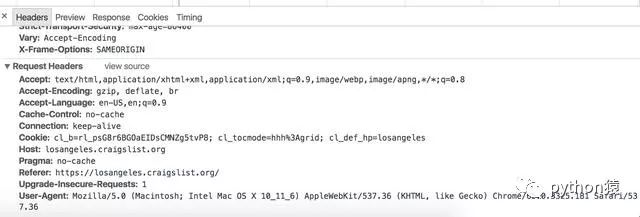
如果你点击了图标并查看,你能找到除了 referer 和 user-agent 之外的大量信息。你能一次性全都实现也可以一个个的实现并测试。无论访问哪个网站,我总是去设置这些信息。请确保你不只是复制粘贴这些信息去访问所有网站,因为这些信息通常会因网站不同而改变。

延迟
在请求之间放置一些延迟总是很好的。我使用 numpy.random.choice() 来实现这一目标,该函数将在我想延迟的服务中传递随机数列表:

如果你还没有使用过 numpy 库,你也可以使用 random choice 来达到同样的目的。
如果你真的很急,那么你可以并行执行 URL ,我之前在此文中解释过了。
结语
Web 爬虫被阻塞的不确定性永远不会变为零,但你总是可以采取一些措施来规避它。我讨论了一些你应该以某种或其他方式在 web 爬虫中实现的策略。
如果你知道其他策略或技巧,请通过分享评论让我获知。一如既往地,期待你的反馈。