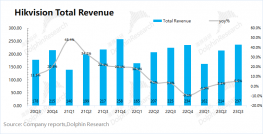
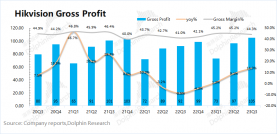
固定场景让车辆识别脱颖而出
经如上介绍,大家会产生新的疑惑:在深度学习算法兴起之前,为什么车牌识别技术能在众多的AI应用中脱颖而出?
对此,宇视黄攀给出了两个字的答案——场景,他进一步分析道:“早期的智能交通虽然采用的是普通图像处理和浅层机器学习技术,但它们与其他AI应用最大的区别在于有标准化场景,如卡口、电警中的六米安装高度、夜间提供爆闪补光、专业的图像调教、45度朝下抓拍角度等,加上车辆的可变动幅度不大,使得抓拍的图像非常清晰,因此在传统算法下也有非常高的识别率,可做到95%~99%的精准识别效果。”
需要说明的是,在2010-2012年,小编曾做过多次车辆抓拍识别测试,即便是采用200万像素智能交通摄像机,只要场景设置得当,识别率可轻松做到99%,很好佐证了宇视黄攀的观点。
但传统方案也有缺陷,一是算法对多种场景的适应性难以进一步提升,如识别率很难趋近于100%;二是传统的浅层机器学习在特征提取、算法设计上对开发人员要求较高,不能很好满足智能交通的复杂场景需求。
在进入到深度学习阶段,大量的场景适应性问题通过丰富的训练素材让算法在训练迭代中得到解决,大幅提升了算法鲁棒性,大大简化了对技术人员的要求。利用新的算法体系做视频结构化,在标准场景下,车牌识别率无限趋近于100%;而在非标准场景下,车牌识别率也能达到98%以上,如辅助卡口的车牌抓拍识别应用。

不过早期与车牌识别应用几乎同时发展的人脸识别需求却始终无法满足,主要受两大因素制约,一是因为人脸并不像车牌那样是一种相对固定的模型,人脸在检测过程中受到姿态、表情、穿戴物、朝向、年龄等各种因素的影响;二是摄像机的安装场景无法达到交通卡口般的标准化水平,受环境影响较大。
通过浅层机器学习算法在这样的条件下完成人脸识别会遇到非常大的挑战,特征提取方式严重依赖工程师的丰富经验:不同场景下,边缘特征、颜色特征等的提取需要工程师具备非常好的数学能力和经验,如此才能设计出最佳特征提取方式;即便如此,人脸识别还要面临人员移动随意性、脸部装饰、环境光照等的制约,识别率难以有保障。这些问题的存在,一度让人脸识别难以在实际场景中得到落地。
利用深度学习算法后,机器可自学习最适合的特征提取方式,对工程师的依赖大大降低。设备通过大数据学习获取人脸特征经验,以此来自动识别人脸,由原来的经验为王转变为以数据为王,更是突破了逆光人脸、阴阳脸、戴墨镜、戴帽子等极端场景人脸的识别障碍。
自此,深度学习让人脸识别得到了爆发式发展,这也使得人脸识别成为安防第一个变现的深度人工智能技术。显而易见,深度学习给人脸识别带来了巨大改变——让理想照进现实,并得到了众安防企业的高度重视,开始将该技术逐步移植到车牌识别、行为分析、事件分析,甚至是大数据等其他AI应用中来。