李彦宏,认错了。
2月14日早上十点,百度的微信公众号发布了一篇非常简短的推文,其内容只有一句话:我们将在未来几个月中陆续推出文心大模型4.5系列,并于6月30日起正式开源。

图源:百度
没有故弄玄虚,没有留下悬念,百度就这样决定将自己最先进的AI大模型开源,很难想象这还是那个曾经坚持“闭源”才是未来的百度。再结合前几天百度宣布文心大模型全模型免费开放使用等消息,不难看出在短短的一个月时间里,百度就在对AI大模型的开放态度上,来了个一百八十度的大转向。
毕竟,百度的CEO李彦宏可以说曾经在2024 年世界人工智能大会以:“开源模型实际上是一种 ‘智商税’,闭源模型在性能和推理成本上都优于开源模型。”“开源模型会越来越落后”等言论引起广泛讨论,甚至一度掀起业内对于AI大模型的开源闭源之争。
不过,最终的结果我想大家都已经看到,百度从闭源走向开源,最终还是跳上了一趟“晚班车”。
AI大模型的闭源与开源之争
作为一个长期关注AI大模型行业的编辑,其实我对于李彦宏的观点也是部分认可的。AI大模型是一个需要长期且巨额投入的行业,很少有公司可以一直顶着巨额的亏损进行运营,所以通过出售闭源模型的API和接受定制模型订单来回笼资金,基本上就是AI应用真正落地开花前仅有的盈利方式。
而且闭源模型可以更好的进行优化,以至于目前全球范围内领先的AI大模型多数都是闭源模型,比如OpenAI的ChatGPT、Google的Gemini和Anthropic的Claude等,这些常年霸占多模态AI排行榜前五的AI都是闭源AI,在性能与使用体验上确实有着不少优势。

图源:OpenAI
在2025年的春节到来之前,闭源模型比开源模型更先进的说法基本上得到了普遍认可。实际上那些排名靠前的开源AI大模型,背后大多也都有闭源模型在支持,比如在最近一次测试中排名全球第七名的Qwen-2.5-Max,就是依托于阿里的通义大模型裁剪出来的简化版模型。
在DeepSeek发布之前,参数量最庞大的开源模型是Meta的LLama 3,其最高版本为405B,也就是拥有405亿的训练参数。即使如此,LLama 3在测试中也无法战胜GPT-4和claude 3 Opus,仅排名第五。
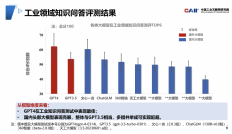
直到参数量高达671B的DeepSeek以蛮横的力量,直接把“闭源才是AI大模型的未来”这句话给粉碎,作为一个开源大模型,DeepSeek在Chatbot的测试中,以1361分的成绩与ChatGPT-4o并列第三,并且超过了ChatGPT-o1的1352分成绩。
可以说,这是第一次有开源AI大模型,在全类别榜单中来到前三的位置,试问这个结果如何不让人感到惊讶呢?当然,更让人惊讶的还是DeepSeek选择将这个超强模型进行全面开源,甚至使用的是最「open」的开源协议。

图源:DeepSeek
在最近半个月时间里,可以看到已经无数的品牌、产品在接入DeepSeek,几乎所有云服务供应商都加班加点完成了DeepSeek的服务器部署,为了揽客甚至大量发放免费额度,吸引用户使用。
DeepSeek让整个市场都看到了开源AI大模型的可怕,在短短半个月里就完成了其他AI大模型都做不到的全生态覆盖。甚至在海外媒体的报道中,印度、英国等国家都有围绕DeepSeek的开源模型开发自己的AI大模型的打算,小到手机大到国家,完全可以用燎原之势来形容。
DeepSeek的成功也让许多人开始重新衡量闭源与开源的侧重,OpenAI的CEO奥特曼就不止一次表示自己错了,“我站在历史错误的一边”,这是奥特曼在回答有关DeepSeek问题时给出的回答,直接承认了此前的闭源策略是错误的,并在随后表示OpenAI正在制定一个开源策略。

图源:维基百科
“人非圣贤孰能无过”,在我看来奥特曼是如此,李彦宏也是如此,犯错不可怕,只要在意识到走错路后及时转回正确的道路,那么一切都还有挽救的机会。这也是为什么百度会在不到一个月的时间里,如此迅速地通过一系列决策,将文心大模型的门彻底敞开,李彦宏用实际行动证明着百度仍然有足够的魄力来应对未来的挑战。
可以说,DeepSeek的开源,所带来的不只是一个AI模型,而是一个截然不同的AI行业。
至于AI大模型未来是否会彻底走向开源,个人的观点是不太可能,更有可能形成开源为基础、半开源为中坚、闭源为塔顶的金字塔型结构。某种程度上,其实和当年的智能手机生态大战相似,开源的安卓与闭源的iOS,两者最终谁都无法取代谁,而是在持续的竞争中共同组成了现在的智能手机生态。
届时的AI行业,或许也会像今天的智能手机市场一样,开源模型(安卓)负责普及和更新底层模块,半开源定制模型负责进一步优化创新(澎湃OS、ColorOS等),闭源模型(iOS)负责提供高性能和高安全性的服务。既拥有开源的普惠特性,又兼容闭源的高性能与安全,对于一个涉及全球所有产业的行业而言,这样的结构或许才更具有活力。
跳上「开源」列车,百度决胜AI未来
百度有机会吗?答案是肯定的,事实上百度从闭源生态上跳车的速度之快,超出了多数人的预料,以至于百度在2月13日和14日分别公布将文心一言完全免费和文心大模型开源后,其股价就开始暴涨,证明市场对于百度的动作有着很高的认可度。
事实上,AI行业还远没有到盖棺论定的时候,DeepSeek用开源证明了整个市场对AI的渴望以及开源的潜力,但是AI模型离真正覆盖全行业,并且应用落地其实还有很长一段路要走。
就拿各种接入DeepSeek的产品来说,大多是做了个入口,通过转接到服务器的方式提供问答服务,与产品本身几乎没有互动,甚至被人吐槽还不如直接下载一个DeepSeek app,操作步骤还少一些。

图源:微博
当下的DeepSeek生态大爆发里,99%的应用和产品或许都可以用“凑热闹”来形容,想要真正体会到DeepSeek在应用层面所带来的改变,还得至少几个月的时间。所以,这就给了其他AI公司追赶的可能,如果文心4.5真的如传闻那样大幅度降低了推理成本,并且在多模态等方面拥有媲美DeepSeek-R1的性能,那么在百度的庞大用户基础和广泛合作伙伴的支持下,并非没有重新突围的机会。
老实说,在国内的一众AI企业中,百度与阿里是少数拥有全场景布局的企业,他们的根须触及我们生活的方方面面,不仅可以加速自身的模型落地,也可以根据需求为某个行业和应用做出针对性的优化和微调。
而在选择了开源这条道路后,百度的AI商用策略也会发生明显改变,比如提供更低成本的AI模型定制方案、超低成本的API接入等,对于一些没有技术团队的企业来说,与其从头开始折腾DeepSeek,不如选择与更成熟的百度合作。
你问为什么不去找DeepSeek合作?很简单,因为DeepSeek几乎让大多数企业都吃了闭门羹,虽然你看到很多产品都联动DeepSeek,实际上都只是接入了第三方的API,DeepSeek本身的API在短暂开放购买后又迅速关闭,并且公司也拒绝了大多数企业的合作请求。
换言之,DeepSeek暂时还没有商业化的打算,不过这也不奇怪,如果真的打算现在就开始走商业化,那么DeepSeek-R1就不会采用近乎完全开源的方式公布。
对于百度来说,这是机会,也是挑战,毕竟如果你的开源模型最终表现还不如DeepSeek-R1,那么更基础的开源底层,仍然会是DeepSeek的天下。当然,现在谈论这些也为时尚早,毕竟我们还不清楚文心模型会以怎样的方式开源,是类似于DeepSeek?还是Qwen和LLama的形式?
不管怎么说,从闭源跳车的百度,现在也已经坐上了开源的快车,并且也在一定程度上扭转了其在用户和开发者心中的形象,在整个AI行业都仍处于探索阶段的当下,百度来得还不算太晚。
来源:雷科技
原文标题 : 李彦宏改错了?!文心大模型走向开源,百度要决胜AI未来