阿里通义千问QwenLM代码在GitHub下架引发信任危机,在开闭源方向选择上,阿里云积极开源,但仍面临变现难题。大模型价格战爆发,技术与市场需求脱节,商业化充满不确定性。
@科技新知 原创
作者丨余寐 编辑丨蕨影
2024年下半年,国产AI大模型并不好过。
近期,AI代码类应用cursor发布,因其强大的编程功能,一时风头无两;紧接着openAI又于9月12日发布了最新模型chatGPT o1,在逻辑推理和编程能力上又提升到一个全新级别,可以说拥有了真正的通用推理能力,国际AI领域的竞争日益激烈。
同样在9月,号称“国服最强”的开源大模型通义千问QwenLM全系列代码在github(全球最大的开源代码托管平台之一)被下架,包括开源新王Qwen2.0在内的项目在访问时全部404。不仅引发了从业者对开源模型稳定性的信任危机,也暴露出国产大模型在商业化道路上的困境。
Part.1
下架风波,回应敷衍

“团队没有跑路,就是github org被无端端flag,所以你们看不到内容,我们已经在联系官方目前也不知道原因。”
阿里高级算法专家,通义千问团队负责人林俊旸在事件发生后迅速在社交平台辟谣。
但这样的回应并没有让AI相关从业者们满意。在此之前,他们中的一些人刚经历过Runway从HuggingFace上删库跑路的风波。Runway以Stable Diffusion系列闻名,一夜之间把自家开源模型清空,让无数正在使用该模型的开发者陷入停摆。
虽然目前github上QwenLM模型代码已经恢复,但对于事件的原因,通义千问团队并没有再做出任何回应。对于开源模型的项目,是否会再次受制于类似事故,从业者们更加茫然和悲观。
开源是阿里通义大模型的重要战略。
阿里云CTO周靖人曾在公开论坛表示:“开发者的反馈和开源社区的生态支持,是通义大模型技术进步的重要助力。”
大模型的训练和迭代成本极高,绝大多数的AI开发者和中小型企业无法负担。从这角度上来看,通义大模型的「全模态、全尺寸」开源战略,长期沉淀的良好口碑为其赢得了一众铁粉。
每有开源动作都会被热切的开发者们早早蹲守。截止2023年10月,阿里云旗下开源社区“魔塔”已有超过2300个模型,开发者超过280万,模型下载数破亿。阿里最新推出的开源模型QWen2系列更是风靡全球,其中Qwen2-72B更是在发布后短短两个小时,就冲上了Huggingface开源大模型排行榜之首,随后又卫冕全球最权威的开源模型测试榜单之首。而阿里最新季度业绩披露,通义千问开源模型下载量已突破2000万。
通义大模型的开源之举,打破了海外闭源大模型对国内开发者们的制约。就像阿里云CTO周靖人所说,“阿里云的初衷不是把模型攥在自己手上去商业化,而是帮助开发者,开源的策略与阿里云的初心完全一致。”在他看来,要在AI创新技术与模型层出不穷的当下,开源是“最佳也是唯一的途径”。
Part.2
开源VS闭源,谁是赢家?

在大模型时代开启之时,开源和闭源就一直争论不休。
百度创始人李彦宏就曾在今年4月举行的百度AI开发者大会上宣称“开源模型会越来越落后。”随后,李彦宏在内部讲话中也对开源模型的局限性表达了明确的看法——虽然开源模型获取和使用便利,但商业化应用中却往往遭遇GPU使用率低、推理成本高等问题。而互联网圈另外一位大佬周鸿祎则表示:“我一直相信开源的力量。”
抛开行业大佬之间的口水战,开源和闭源,两种截然不同的开发方式在当今的大模型发展中各有千秋。
从阵营上看,开源模型如meta的Llama系列、斯坦福的Alpaca、国内的阿里通义大模型等展现了社区驱动的快速进步和创新。而以OpenAI的GPT系列、Anthropic 的Claude大模型、百度的文心大模型、华为的盘古大模型等都选择了闭源的形式,保持着技术领先和商业应用的优势。
开源模式促进了大模型技术的共享与创新,而闭源模式则保障了商业利益和技术优势,为大模型的商业化提供了支持。
有从业者声音认为,从模型侧来讲,开源模型当前还是稍逊于闭源模型。但随着更多开源模型的迭代,开源的能力也在快速跟上。比如通义大模型Qwen2.5模型性能已经全面赶超GPT-4 Turbo。
“从模型质量上来看,开源模型由于其代码的公开性,更容易在社区得到测试和改进;但闭源模型在研发时,模型的数据语料质量、丰富程度以及算力规模,团队的算法能力和背后强大的资金支持等因素,保证了闭源模型的高质量输出。”
上述从业者也提到,数据安全对于大模型来说非常重要,训练时会牵涉到用户的隐私数据,抓取也可能存在攻击性数据。开源模型因为要开放给更多用户,在安全和隐私方面会更加重视,安全专家可以进行代码审查,及时发现并修复潜在的安全风险;而闭源模型因为其代码不公开,有专业的安全团队进行安全防护和漏洞修复,可以减少由于外部攻击导致的安全隐患。在业内人士看来,开源和闭源并非二元对立的关系。
Part.3
通义千问,路在何方?

比起开源和闭源之争,如何实现商业化才是各家大模型当前急需解决的难题。
纵观阿里通义大模型的体系,可以分为大模型底座和应用端产品模型两个层面。2022年9月,达摩院发布“通义”大模型系列,打造业界首个AI底座。经过一年多的技术爆发,通义大模型已经从初代升级至2.5版本。为了满足不同计算资源需求和应用场景,通义团队还推出了参数规模从5亿到1100亿的八款大语言模型,以及包含了多个面向不同应用场景的模型,如Qwen-VL(视觉理解大模型)、Qwen-Audio(音频理解大模型)等。
除了底层大模型的研发,通义团队在应用端产品也卯足了劲。在去年10月的阿里云云栖大会上,CTO周靖人一口气发布了八款产品模型:包括通义灵码(智能编码助手)、通义智文(AI阅读助手)、通义听悟(AI工作学习助手)、通义星尘(个性化角色创作平台)、通义点金(智能投研助手)、通义晓蜜(智能客服助手)、通义仁心(个人健康助手)、通义法睿(AI法律顾问)。同时,通义千问正式上线了APP,所有用户都可通过“通义APP”直接体验最新模型能力;开发者可以通过网页嵌入、API/SDK调用等方式,将上述所有模型集成到自己的AI应用和服务中。
基于通义大模型的开源属性,商业化更是一个复杂的挑战。
「科技新知」梳理下来,目前大模型的商业化模式大致可分为四类。从C端市场来看:一是直接提供API接口,用户通过按量使用来收费;二是大模型赋能产品带来的需求与价格增长,如chatGPT、Midjourney等产品的付费使用。从B端市场来看,一是AI功能带来的流量增长,进而收取广告费用;二是通过AI对企业内部赋能,帮助企业降本增效,如文心大模型接入百度系产品,帮助产品提效。
目前看来,阿里似乎是在ToB和ToC的商业化道路上同时摸索前行。2023年4月,阿里巴巴宣布所有产品未来将接入“通义千问”大模型,进行全面改造。而在企业赋能上,阿里云把从飞天云操作系统、芯片到智算平台的“AI+云计算”这些AI基础设施和通义大模型能力向所有企业开放,未来每一个企业既可以调用通义千问的全部能力,也可以结合企业自己的行业知识和应用场景,训练自己的企业大模型。同时,通义灵码、通义智文、通义听悟等在内的八款产品模型,也受到了不少C端用户的肯定。
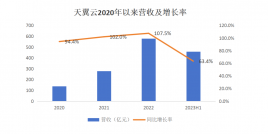
变现之路尚未明朗,AI大模型的价格战却已经打响。今年5月以来,字节、阿里、百度、智谱AI等多家国内大模型厂商均调整了旗下大模型产品的定价策略,通义千问主力模型Qwen-long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%。
这也深层次反应了大模型厂商在技术、市场和战略等多方面的竞争到来。从商业化的角度来说,纯粹的价格战能在短期吸引用户,形成头部的虹吸效应,但长期选择上,没有技术创新作为支撑,难以形成持久的竞争优势。
大模型落地应用想象空间巨大,但落地难度同样不小。例如,将大模型直接应用于具体场景,比如医疗健康或法律咨询领域时,实际操作的挑战便显现出来。
在降本增效的大背景下,B端客户在选择大模型时也会更加注重成本和收益。如何通过细分市场企业精准定位市场需求,提供针对性解决方案,也是通义大模型在商业化布局中需要深思的。
而在C端市场,对于大多数消费者来说,AI技术的实用性尚未达到不可或缺的地步,各家应用的功能目前也并非不可替代。
这是通义大模型商业化的困境,也是多数AI大模型企业的难题。
原文标题 : 突遭下架,“国服最强”开源模型将何去何从?