作者:一号
编辑:美美
中国大模型被抄袭,怎么不算是某种层面上的国际认可呢?
5月29日,斯坦福大学的一个AI研究团队发布了一个名为「Llama3V」的模型,号称只要 500 美元就能训练出一个 SOTA 多模态模型,且效果比肩 GPT-4V、Gemini Ultra 与 Claude Opus 。
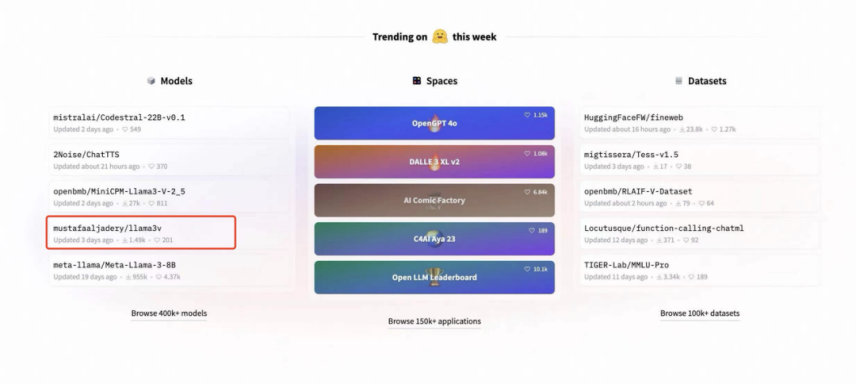
论文作者一共有三位,分别是Mustafa Aljaddery、Aksh Garg、Siddharth Sharma,其中两位来自斯坦福,并且集齐了特斯拉、SpaceX、亚马逊还有牛津大学等各种机构的相关背景,在外人看来,这是典型的业界大牛。所以宣布发布这个模型的推文很快浏览量就超过了30万,这个项目也冲到了Hugging Face的首页,而且别人试用了一下,效果是真的不错。
但是这个大模型最近却“删库跑路”了,怎么回事呢?
美国名校居然抄袭中国大模型?
在Llama3V发布后没几天,在X平台还有Hugging Face上就出现了一些怀疑的声音。有人认为,Llama3V实际上是“套壳”了面壁智能在5月中旬发布的8B 多模态小模型 MiniCPM-Llama3-V 2.5,但并没有在Llama3V的工作中表达过任何对 MiniCPM-Llama3-V 2.5的致敬和感谢。
面壁智能是一家中国AI大模型公司,其核心团队成员包括来自清华大学自然语言处理与社会人文计算实验室 (THUNLP)的成员,如 CEO 李大海、联合创始人刘知远等。
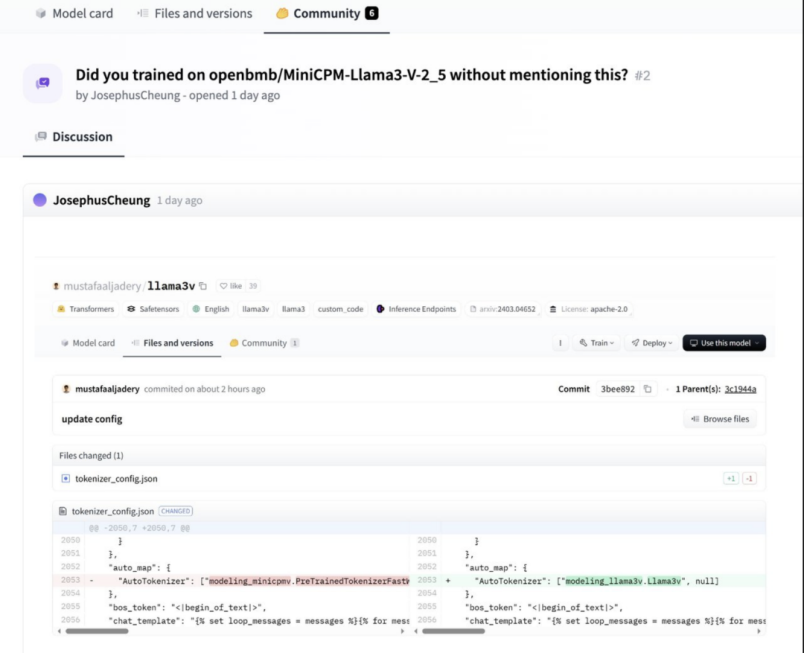
对此,这个斯坦福AI团队回应称,他们「只是使用了 MiniCPM-Llama3-V 2.5 的 tokenizer」,并「在 MiniCPM-Llama3-V 2.5 发布前就开始了这项工作」。然而求锤得锤,随着好心网友的深挖,发现这两个模型的模型结构、代码、配置文件,简直一模一样,只是改了变量名而已。

但是,网友摆出证据质疑Llama3V团队后,团队采取的做法却是删评删库,不少跟这个项目相关的网页,不管是GitHub还是Hugging Face,统统都变成了404。摆证据不听,那网友就找到的事件的另一当事方,也就是面壁智能那里,把一系列的证据都亮了出来。
面壁智能一看,就让这两个模型做了测试,发现这两个模型「不仅正确的地方一模一样,连错误的地方也一模一样」,这如果还是巧合就有点说不过去了。随后他们找到了一个关键性证据,那就是识别清华简。这个实际上是MiniCPM-Llama3-V 2.5的特有功能之一。
清华简是一种非常罕见、在战国时期写在竹子上的中国古代文字。他们在训练的时候,使用的图像是从最近出土的文物中扫描得来的,而面壁智能进行了标注。因此,可以说,除了面壁智能,其他的大模型基本上并不会具备这一功能。况且Llama3V还是美国团队研发的,按理说应该并不会特意去做这一个功能。但是,实际上,Llama3V和MiniCPM-Llama3-V 2.5的识别情况极其相似,这基本就是实锤了。

证据面前,认错态度却很迷
种种证据面前,斯坦福的这个团队依旧不承认抄袭,而是选择下架了几乎所有与Llama3V相关的项目,但却做了下面的声明:
非常感谢那些在评论中指出与之前研究相似之处的人。
我们意识到我们的架构非常类似于OpenBMB的“MiniCPM-Llama3-V 2.5,他们在实现上比我们抢先一步。
我们已经删除了关于作者的原始模型。
但随后又光速滑跪,项目其中的两位作者Siddharth Sharma以及Aksh Garg和另一位作者,来自南加利福尼亚大学的Mustafa Aljadery切割,指责其为项目编写了代码,但没有告知她们有关面壁智能的事,他们两个人更多只是帮助他推广这个模型。
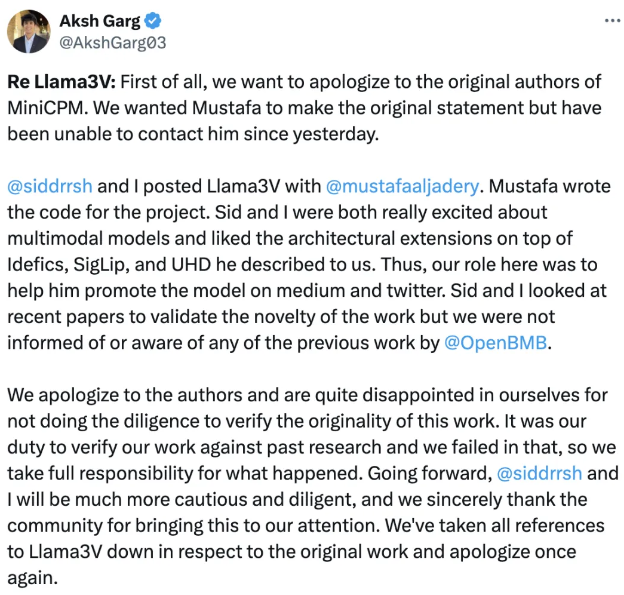
这让不少网友嘲讽,靠发发推文推广下就能成为项目作者之一,这名头来得也太简单了。因此,斯坦度人工智能实验室主任Christopher Manning下场开喷,说这是“典型的不承认自己错误!”
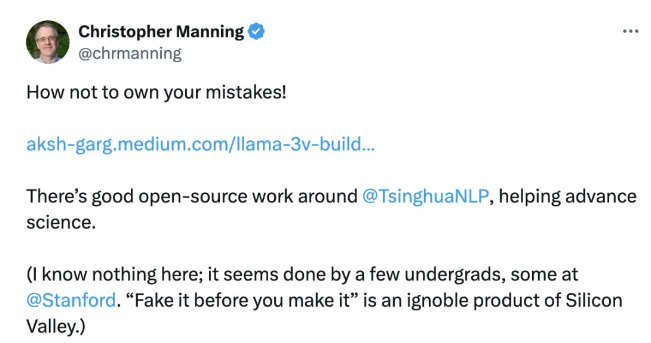
对此,面壁智能CEO在昨天回应称“也是一种受到国际团队认可的方式”,首席科学家刘知远也表示,“该团队三人中的两位也只是斯坦福大学本科生,未来还有很长的路,如果知错能改,善莫大焉”。
中国大模型缺少国际团队认可
尽管本次事件具有极大的戏剧性,但实际上,这个事件之所以能引起人们的注意,主要是因为Llama3V不仅有名校名企的背书,而且确实拥有不错的实力,但这也引起了人们的反思。
谷歌DeepMind研究员、ViT作者Lucas Beyer提到,Llama3-V是抄的,但成本低于500美元,效果却能直追Gemini、GPT-4的开源模型确实存在,那就是面壁智能的MiniCPM-Llama3-V 2.5,然而,相比起Llama3V,MiniCPM得到的关注要少得多。主要原因似乎是这样的模型出自中国实验室,而非常春藤盟校。

而Hugging Face的负责人Omar Sanseviero也说,社区一直在忽视中国机器学习生态系统的工作。他们正在用有趣的大语言模型、视觉大模型、音频和扩散模型做一些令人惊奇的事情。
包括Qwen、Yi、DeepSeek、Yuan、WizardLM、ChatGLM、CogVLM、Baichuan、InternLM、OpenBMB、Skywork、ChatTTS、Ernie、HunyunDiT等等。

的确,从大模型竞技场上来看,中国的大模型实际上表现并不差,例如来自零一万物的Yi-VL-Plus在模型一对一PK的视觉大模型竞技场中排名第五,超过了谷歌的Gemini Pro Vision,智谱AI和清华合作的CogVLM也跻身前十。而在其他项目的比试中,中国大模型也往往榜上有名。
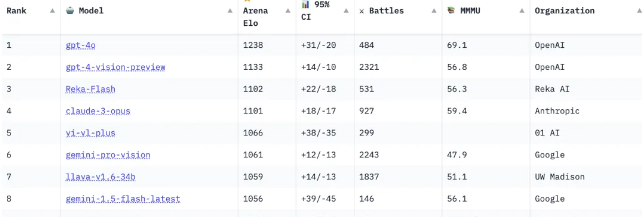
即使具备这样的实力,但国产大模型不仅在国际上不受待见,在国内也常常深陷舆论泥淖,被贴上了“别人一开源,我们就自主”还有“套壳”等标签。而这次事件,可以很好地说明,实际上,中国大模型中也有一些出色的,尽管面对国际领先模型仍有显著差距,但中国大模型已经从以前的nobody,成长为了AI领取的关键推动者之一,一些关于中国大模型的成见需要被打破。
原文标题 : 新火种AI|倒反天罡!美国名校斯坦福AI团队抄袭中国大模型