最近,又一个概念火了——向量数据库。
随着大模型带来的应用需求提升,4月以来多家海外知名向量数据库创业企业传出融资喜讯。
4月28日,向量数据库平台Pinecone宣布获得1亿美元(约7亿元)B轮融资;
4月22日,向量数据库平台Weaviate宣布获得5000万美元(约3.5亿元)B轮融资;
4月6日Chroma获1800万美元种子轮融资;
4月19日Qdrant获750万美元种子轮融资。
国内方面,星环科技、北交所云创数据等公司的股价连续异动,其中云创数据自底部以来股价已接近翻倍。
7月4日,腾讯云正式发布向量数据库Tencent Cloud VectorDB,预计8月上线腾讯云官网。
一连串的市场动作,都展示了向量数据库的爆红。那么,什么是向量数据库,到底有啥用?

什么是向量数据库?
当你在网上看到一张壁纸,你想知道这是哪个国家的美景,却不知道如何搜索;或者,在阅读一篇文章时,你想深入了解这个话题,寻找更多的观点和资料,却不知道该如何精确描述。
这时,你需要的是一个能够理解你的意图,为你提供最相关的结果,让你轻松找到你想要的信息的工具。
这就是向量数据库(Vector Data Base),它就像一个超级大脑,帮助你解决这些问题。
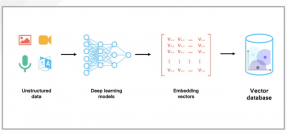
所谓向量数据库,是一种专门用于存储、 管理、查询、检索向量的数据库,可以把复杂的非结构化数据通过向量化,处理统一成多维空间里的坐标值。
目前,向量数据库主要应用于人工智能、机器学习、数据挖掘等领域。
具体来看,向量数据库被广泛地用于大模型训练、推理和知识库补充等场景:
●支撑训练阶段海量数据的分类、去重和清洗,给大模型的训练降本增效;
●通过新数据的带入,帮助大模型提升处理新问题的能力,突破预训练带来的知识时间限制,避免大模型出现幻觉;
●提供一种私有数据连接大模型的方式,解决私有数据注入大模型带来的安全和隐私问题,加速大模型在产业落地。
简而言之,向量数据库可以解决大模型预训练成本高、没有“长期记忆”、知识更新不足、提示词工程复杂等问题,突破大模型在时间和空间上的限制,加速大模型落地行业场景。
向量数据库的发展
在向量数据库出现之前,大家普遍使用的是关系型数据库,如MySQL、Oracle等,这些数据库以表格的形式存储数据,适合存储结构化数据。但对于非结构化数据,如文本、图像、音频等,处理起来就相对困难。
此外,关系型数据库在处理大规模数据时,性能会下降,不适合大数据处理。这就像是在一个拥挤的图书馆里找一本书,你知道它在哪个书架上,但是找到它还需要花费大量的时间。
而向量数据库和传统数据库的不同点在于,向量数据库处理的是各种AI应用产生的非结构化数据,通过近似查进行模糊匹配,输出的是概率上的提供相对最符合条件的答案,而非精确的标准答案。
举例来说,传统数据库做图片检索可能是通过关键词去搜索,向量数据库是通过语义搜索图片中相同或相近的向量并呈现结果。理论是向量之间的距离越接近,就说明语意越接近,效果也有最相似。
随着时间的推移,向量数据库开始在不同的领域和应用中不断成长和进化。从20世纪90年代末到2000年初,美国国立卫生研究院和斯坦福大学都开始使用向量数据库。
2005年到2015年间,随着基因研究的深入和加速,向量数据库也在并行中增长,像UniVec 数据库这样的工具在2017年就已经被广泛使用,它们在基因序列比对、基因组注释等领域发挥了重要作用。
2017年和2019年之间,向量数据库开始爆炸式增长,它被应用于自然语言处理、计算机视觉、推荐系统等领域。这些领域都需要处理大量和多样化的数据,并从中提取有价值的信息。
向量数据库通过使用诸如余弦相似度、欧氏距离、Jaccard 相似度等度量方法,以及诸如倒排索引、局部敏感哈希、乘积量化等索引技术,实现了高效和准确的向量检索。
目前各大厂商使用的推荐系统、以图搜图、哼唱搜歌、问答机器人等应用,其内核都是向量数据库。
在今年,向量数据库开始被用于与大语言模型结合的应用。
它为大语言模型提供了一个外部知识库,使得大语言模型可以根据用户的查询,在向量数据库中检索相关的数据,并根据数据的内容和语义来更新上下文,从而生成更相关和准确的文本。
这些大语言模型通常使用深度神经网络来学习文本数据中隐含的规律和结构,并能够生成流畅和连贯的文本。
向量数据库 过使用诸如BERT、GPT等预训练模型将文本转换为向量,并使用诸如FAISS、Milvus等开源平台来构建和管理向量数据库。
总体而言,向量数据库成功地解决了很多挑战,并为人们带来了很多价值。
针对传统关系型数据库难以处理的大规模数据、低时延高并发检索、模糊匹配等领域,向量数据库通过数据的向量化来满足特定需求,尤其适用于人工智能领域。
让行业大模型具备know how能力
随着AI大模型的崛起,向量数据库的爆红也就不难理解。
一是,在现实世界里,非结构化数据是“主流”。根据Gartner的数据,非结构化数据占企业生成的新数据比例高达90%,并且增长速度比结构化数据快三倍。
而生成式AI大模型进一步带来了非结构化数据的暴增,也相应推动了对向量数据库的需求。
向量数据库的一大优势在于,能够通过机器学习方法处理和理解来自不同源的多种模态信息,如文本、图像、音频和视频等。
二是,越来越多的大模型从业者认为,所有的行业都值得被AI重新做一遍。
因此,建立在不同行业的垂直大模型,成为大家的切入点,而向量数据库是行业大模型具备“行业knowhow”能力的必经之路。
这背后是,AI大模型的产生,需要经历大量反复的训练和调试。虽然通用AI大模型能回答一般性问题,但在垂直领域服务中,其知识深度、准确度和时效性有限。
而利用向量数据库结合大模型和自有知识资产,可以构建垂直领域的AI能力。向量数据库存储和处理向量数据,提供高效的相似度搜索和检索功能。
正如东北证券观点,AI化的本质则是向量化,向量化计算成本高昂,海量的高维向量势必需要专门的数据库进行存储和处理,向量数据库应运而生。
向量数据库在拓展AI全新应用场景的同时,也将对传统数据库产品形成替代,进而成为AI时代的Killer App。
目前,向量数据库是一个亟待引爆的蓝海市场。
据公开资料显示,向量数据库市场空间巨大,尚处于从0-1阶段,预测到2030年,全球向量数据库市场规模有望达到500亿美元,国内向量数据库市场规模有望超过600亿人民币。
未来随着生成式AI大模型开发量和使用量的增长,向量数据库的应用有望快速增长。
而国内外众多玩家如传统数据库厂商、初创数据库厂商、云厂商、跨界厂商等都已跃跃欲试,提前开始布局向量数据库,做好了应对AI大模型时代的准备。
相关阅读
生成式AI大模型,或将撼动云服务市场格局
GPU受限,国内AI大模型能否交出自己的答卷?
从“存算一体”到“存算分离”:金融核心数据库改造的必经之路
数据库市场迎来大变局,“后来者”云原生数据库将成企业必选项
中国如何翻过数据库这座大山?
【科技云报道原创】
转载请注明“科技云报道”并附本文链接
原文标题 : 向量数据库:c时代的下一个热点