
PG:checkpoint是什么
Checkpoint是PG中的核心概念。然而会有用户对此比较陌生,不知道如何调优。本文解释checkpoint及如何调优,希望对数据库内核理解有所帮助。
PG如何写数据
详细讨论checkpoint前,理解PG是如何write数据的非常重要,看下面的图:
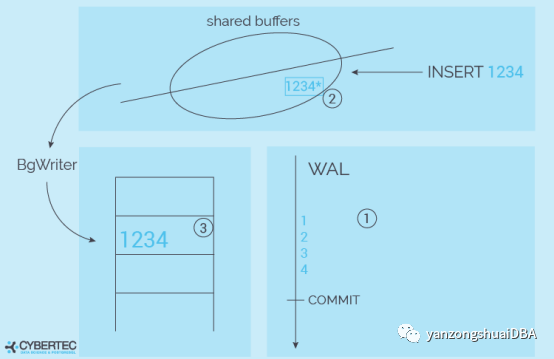
重要的假设是crash会发生在任何时间。为什么和这个相关?需要确认数据库永远不会被破坏。我们不能直接将数据写入数据文件。为甚?假设要将“1234”写入数据文件,如果在“12”后面崩溃,结果将是表中某个位置的一个元组被破坏,索引条目可能丢失等。我们必须不惜一切代价防止这种情况发生。
因此需要更加复杂的数据写入方法。PG首先将数据写入WAL,WAL就像一个包含二进制变化的顺序磁带。如果添加一行,WAL可能包含一条记录,用于记录数据文件哪些地方改动了,可能包含一组索引记录改动的指令、可能需要写入一个额外的页等,仅包含一系列变化。
数据一旦写入WAL,PG将会对共享缓存区中的数据页进行更改,注意数据文件中仍没有数据。现在有了WAL条目及共享缓冲区的脏页。如果一个读取请求来了,可从缓存中找到,而不用到磁盘上读取。
某个时刻,内存中的脏页会由后台写入进程写入磁盘。这里最重要的一点是,数据可能会被乱序写入,这个是没有问题的。如果用户想读取数据,PG先从共享缓冲区中获取。因此脏页的写入顺序与此无关。甚至可以晚一点写入,以增加一次sync的量。
删除WAL
WAL不能无限写入,需要回收空间。这就是CHECKPOINT需要干的活之一。
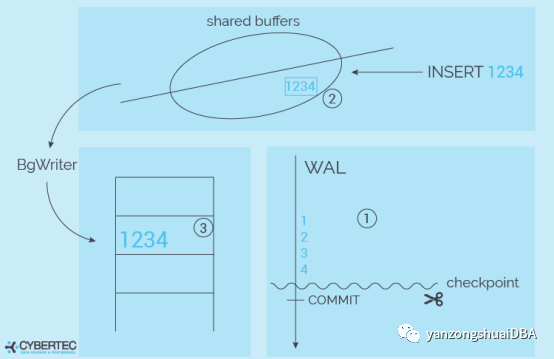
Checkpoint的目的就是确保脏页刷写到磁盘,然后该脏页对应的WAL及之前的WAL就可以删除回收了。PG的方法启动一个checkpoint进程,将bgwriter进程没有刷写的刷写到磁盘。但是这个过程并没有尽可能快的刷,我们需要使IO平稳,保证稳定的响应时间。
控制checkpoint平稳的参数为:
test=# SHOW checkpoint_completion_target;checkpoint_completion_target------------------------------0.5(1 row)
到下个checkpoint开始前完成刷写一半。真实情况下对于大多数负载0.7-0.9就可以了,但可以随意设置。注意PG14中这个参数就会取消了,硬编码值为0.9。下一个问题是:什么时候进行checkpoint呢?参数为:
test=# SHOW checkpoint_timeout;checkpoint_timeout--------------------5min(1 row)test=# SHOW max_wal_size;max_wal_size--------------1GB(1 row)
如果系统的负载比较低,在一段时间后进行checkpoint。默认值是5分钟,但建议增加这个值以提高写入性能。注意,请随意修改这个值,仅会影响性能,不会以任何方式伤害数据库,除了性能没有数据会有风险。
max_wal_size有点棘手,这个是个软限制,不是硬限制。因此WAL会超过这个值。这个值为了告诉PG可以堆积多少WAL,从而挑战checkpoint。现实中,提高这个值会消耗更多空间,但是会提高性能。
为啥不将max_wal_size设置成无限大呢?首先很明显,这样就需要更多空间。另外,一旦数据库崩溃,PG就需要从上个checkpoint处开始回放,这样回放的时间就非常长了。如果检查点的距离增加,性能确实会提升,但是所做的和想要达到的效果有限,从某种意义上说,在这个问题上投入更多存储空间不会改变任何事情。
后台写进程会将脏页刷写到磁盘,然而许多情况下,更多工作是由checkpoint进程本身完成,因此关注checkpoint比后台写进程有意义。
min_wal_size:神秘参数
min_wal_size 和max_wal_size有什么区别呢?如果PG空闲,会逐渐将WAL量减少到min_wal_size,这是个缓慢的过程,不是立即一蹴而就。假设本周内有高写负载,但是在周末会空闲。礼拜五下午,WAL量会很多,但是周末,会渐渐减少。当到周一后,WAL量又会增加。
因此最后将min_wal_size的值设置的不要太小。









